





用户在使用我们基于DolphinScheduler二开的调度平台时,发现一个bug,工作流执行到一半无法继续执行也无法停止。
没想到这个bug比较棘手,解决起来花了不少时间,本文记录解决这个bug的过程。
1、问题发生
两个星期前,用户报了个bug,线上一个工作流,从上往下的任务都执行成功,但是无法继续往下运行,工作流一直处于运行中的状态,截图如下:
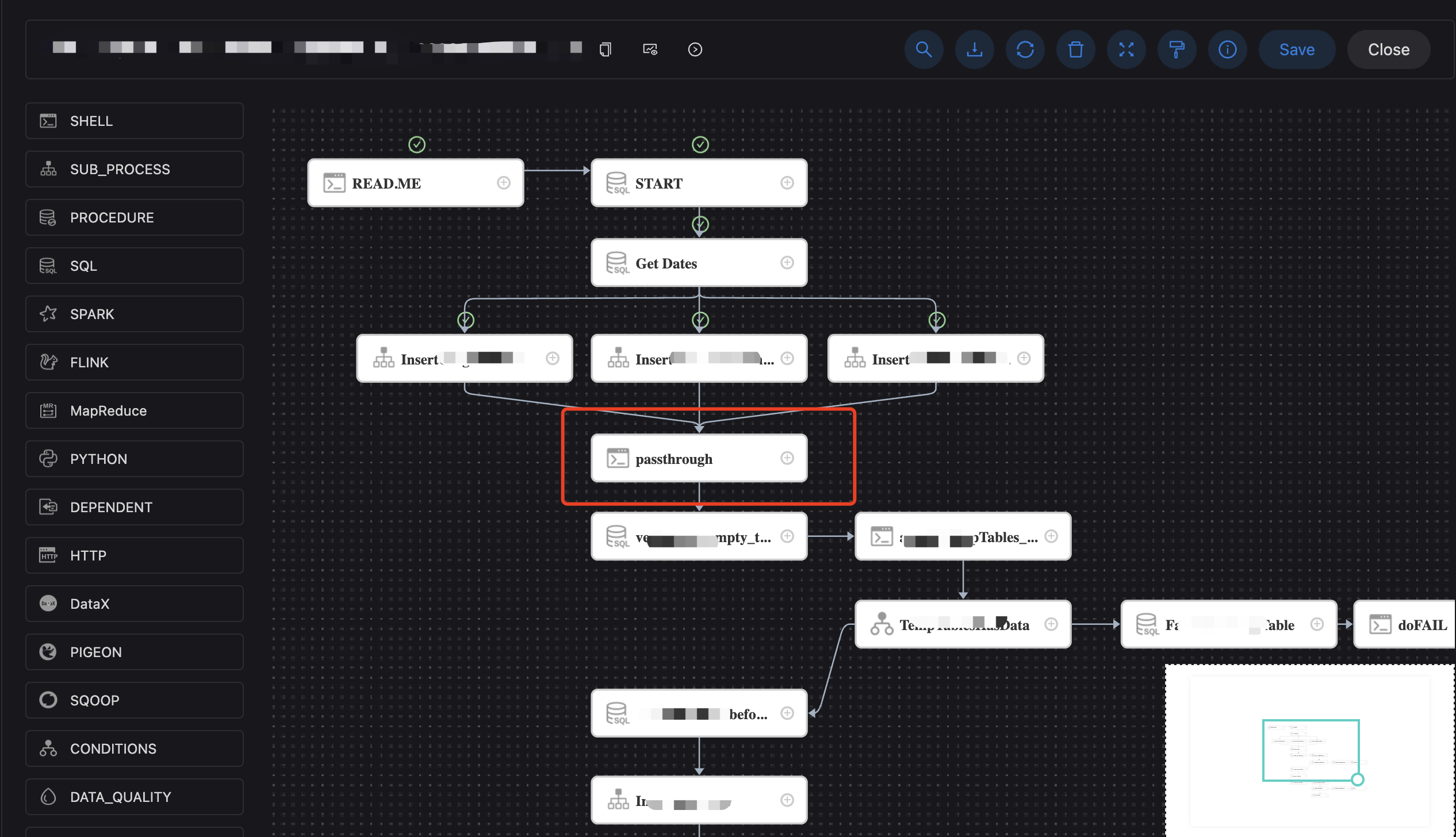
接到这个bug之后去试了一下,可以复现出现。
于是看了一下日志。
错误信息如下:
1 | 2023-08-17 05:57:15.583 +0000 [ERROR] org.apache.dolphinscheduler.server.master.runner.WorkflowExecuteRunnable:[308] - [WorkflowInstance-831834][TaskInstance-1279299] - State event handle error, get a unknown exception, will retry this event: TaskStateEvent(processInstanceId=831834, taskInstanceId=1279299, taskCode=0, status=null, type=TASK_STATE_CHANGE, key=831836-0-831834-1279299, channel=null, context=null) |
1266行 通过看代码可以发现是这个报了一个npe。
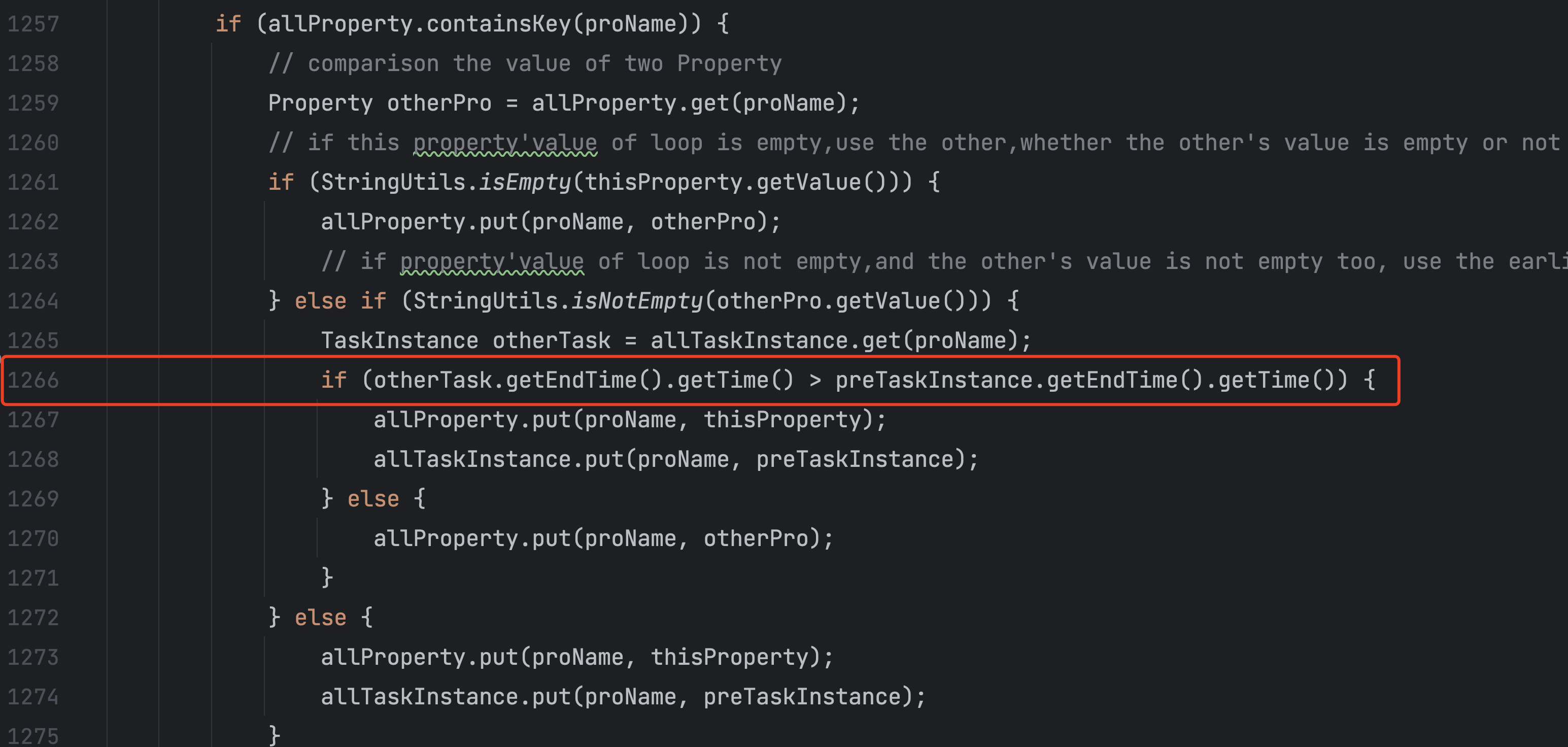
通过代码逻辑,可以大概看出来,是task的endtime为null。
看一下调用的上下文,基本上是在task的参数在透传的时候调用这个方法,然后出现的问题。
然后没有其他更多有价值的信息了。
可以看到是新的任务无法启动成功,一直在死循环报错,所以工作流无法启动,任务无法提交。页面上也看不出来任何信息,感觉就是卡住了。
2、问题排查
定位到代码出问题的地方,理论上来说解决应该不难。
由于是在产线,所以日志不多,拿不到更多信息。所以下一步去测试环境部署一下一模一样的工作流,然后运行一下看看,再本地debug一下,看下内存里的数据,再确认一下问题。
从这里开始,事情就诡异了起来。
我把工作流一模一样手动部署到测试环境。
运行了一下。
结果运行成功。
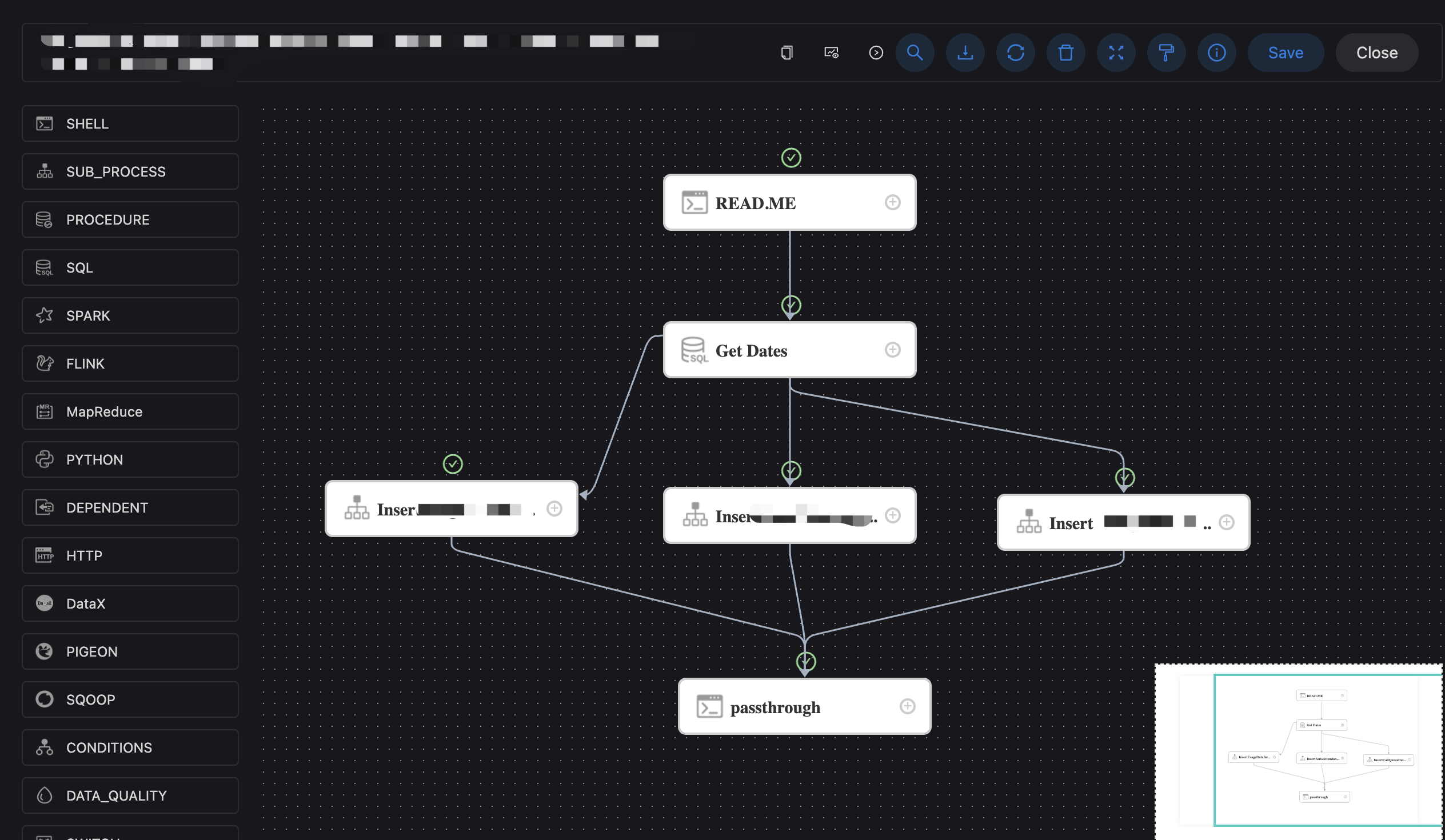
中途没有卡主,一路顺畅执行成功。
那我怀疑是不是两边代码不一致导致的,那这个问题就更好查了,找出不一样的代码,基本上问题就解决了。
于是将线上分支重新打了个包,然后部署到测试环境重新测试。
结果运行成功。
那会不会不是两边数据库有问题,导致运行结果不一致。
我把产线环境的数据库复制了一份,然后把测试环境指向这个复制的数据库,再进行测试。
结果运行成功。
这时怀疑这个事件在产线是不是百分之百必现的。
会不是是概率事件,只不过是巧合导致测试环境和产线结果不一致?
我在产线又运行了三五次工作流。
结果全部都无法正常执行结束。
所以在产线100%必现。
我在测试环境又运行了多次工作流。
结果全部正常运行结束。
所以在测试环境100%正常。
完全一样的代码,完全一样的数据库。
完全不同的结果。
那变量还有什么呢,两边机器不一样,但是会影响运行的结果吗?
为了排除变量,将这个工作流部署到预发环境试一下,又是一个独立的环境,独立的机器,结果运行成功。
奇了怪了,说明跟环境完全没关系。
3、陷入死局
我们来梳理一下目前掌握的情况。
这个bug,在产线必现,除了产线,测试环境同样的代码同样的数据库也无法复现。
不好排查,因为只有线上能复现,拿不到太多信息,无法debug,不太好找原因。
那先添加点日志,虽然error log说这个enttime为null,那加个日志打印一下,看看这块数据具体值是什么,是否是这个task的状态没有更新到,所以没有endtime。
于是跟着下一次发布,添加了一些日志到线上。
重新启动工作流,看到这块的日志,task的endtime确实为null,但是task的状态显示是成功的,也就是被更新了。
1 | 2023-08-29 03:18:19.163 +0000 [INFO] org.apache.dolphinscheduler.server.master.runner.WorkflowExecuteRunnable:[1267] - [WorkflowInstance-992849][TaskInstance-1419795] - otherTask : TaskInstance(id=1419793, name=InsertCallQueueDataIntoTempTable, taskType=SUB_PROCESS, processInstanceId=992849, taskCode=10447712796544, taskDefinitionVersion=3, processInstanceName=null, processDefinitionName=null, taskGroupPriority=0, state=TaskExecutionStatus{code=7, desc='success'}, firstSubmitTime=Mon Aug 28 08:09:42 UTC 2023, submitTime=Mon Aug 28 08:09:42 UTC 2023, startTime=Mon Aug 28 08:09:43 UTC 2023, endTime=null, host=dolphinscheduler-master-1.dolphinscheduler-master-headless:5678, executePath=null, logPath=/opt/dolphinscheduler/logs/20230828/10373487528525_46-992849-1419793.log....... |
问题其实比较清晰了,两个可能,第一个是endtime没有更新,第二个是endtime更新了,但是在某个地方被更新成null了。
由于task的状态已经被更新了,所以我倾向第二个原因,也就是endtime在某个地方更新成null了。
那就去看一下代码,全局搜索可以设置endtime为null的地方。
果然发现了一个:
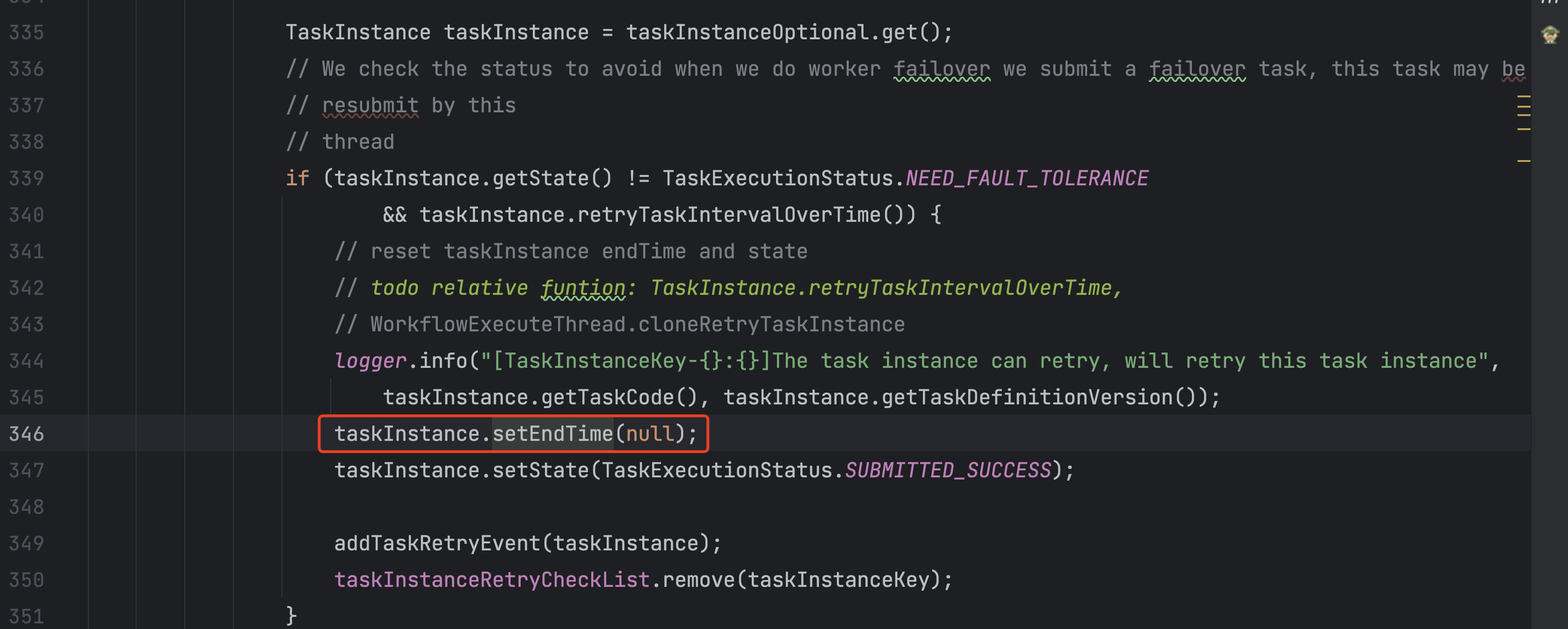
这里的逻辑会把endtime设置为null,当时心中一喜,觉得应该八九不离十了。
如果会走这个逻辑,那么上面那行日志是一定会打出来的,我去搜一下日志,基本上就能判断是这里的问题。
1 | logger.info("[TaskInstanceKey-{}:{}]The task instance can retry, will retry this task instance", |
结果问题来了。
这行日志搜不到。
那就意味着这个逻辑没进来。
那还有其他地方会把endtime改为null吗?
搜了下代码,没有看到类似的逻辑了。
这么看来,endtime在某个地方更新成null这个想法感觉不成立了。
那就只能是endtime没有更新了。
task的状态是修改了的,说明task是进入了修改逻辑,只是恰好end time没有修改?
持着疑惑的态度,进入代码进行搜索。
发现了几个更新task的地方。但是每个更新task的地方都更新了end time。
一时陷入僵局。
好,当前工作流下面是a->(1 2 3 )->b的情况,那我来排查一下,中间这个三个任务是不是有什么问题。
我把称呼中间三个任务为1 2 3,我们目前已知1 2 3同时运行,会无法继续执行。
那单独运行1 2 3会有问题吗?
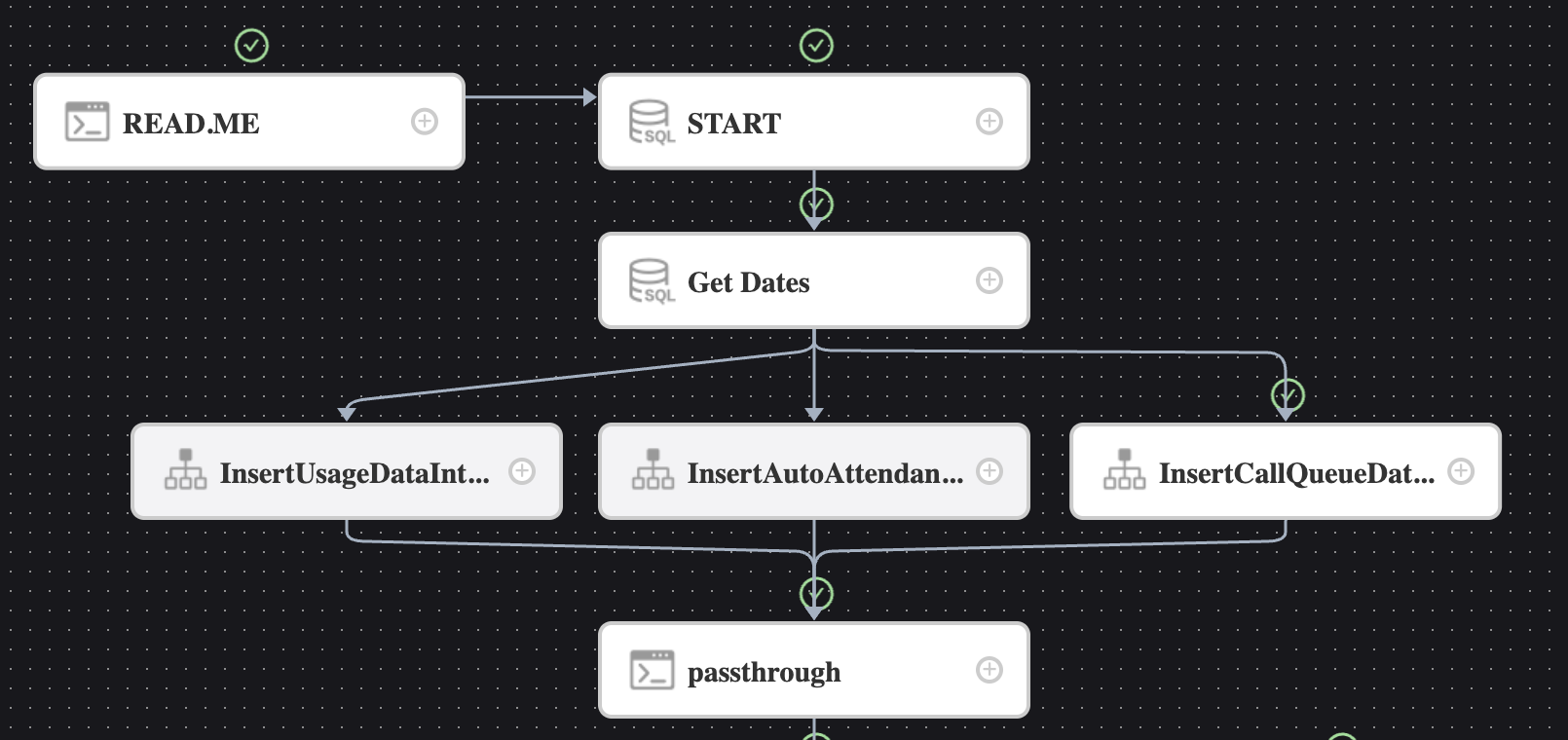
测试出来1 2 3分别运行整个工作流运行是成功的。
那我们穷举,分别运行1 2、1 3、2 3是什么结果呢?
结果2 3运行成功,1 2运行失败、1 3运行失败。
但是单独运行1也是成功的。
这个情况无法解释。完全看不出有什么规律或者特点。
知道出问题的地方,但是看不出来问题。
测试环境无法复现,不好排查。
加上这段时间比较忙,这个问题也只有一个用户爆出来,加上确实找不到问题,怀疑思维陷入僵局,所以一度搁置。
后面用户联系我说他们团队依赖这个工作流,所以需要尽快解决,于是又将该问题提上日程。
重新审视一下该问题,在产线100%必现,在测试环境100%正常。在代码、数据库完全都一样的情况下,这是不可能发生的事情,所以一定还有我忽略的点。
4、发现切入点
但是感觉我已经陷入思维误区了,我去找其他同事沟通,尝尝开阔思路。
我问他,产线和测试环境,有什么不一样。
他告诉我,代码、数据库不一样。
我说还有呢?
我说是不是配置文件什么的不一样,他说对。
然后他说产线有多个master、多个worker。
测试环境只有一个。
醍醐灌顶,那会不会这个其实是根本原因呢?
虽然我不知道多个master、多个worker会对运行结果有什么影响,但是这是两个环境的区别。
我灵敏的感觉这里很有可能就是原因。
下面就是着手验证我们的想法。
是不是跟这个原因有关。
我们把测试环境的master和worker改成3个,再次在测试环境运行工作流。
结果工作流卡住了,复现出来了!
说明问题应该解决了80%了。
下一步再缩小变量,把worker改成一个,还是多个master,看下问题是否还存在。
验证问题依然存在。
那如果是一个master,多个worker呢?
结果问题不存在,工作流正常运行结束。
OK,现在已经可以清楚的定位到问题了,多个master会导致触发这个bug。
如果是两个master,一个worker呢?
问题依然存在。
5、解决问题
我们接下来开始排查具体的原因。
当时我的直觉是多master通信之间的问题。
因为这个大的process是多个子process,我感觉在运行的过程中,不同的子process被调度到了不同的master,然后在子process运行结束后,回调主process的时候出现了问题,没有更新子process对应的task的状态。
但是有一点说不通,就是task的状态变了,只有endtime没变。
但是感觉大体是这个问题,接下来就是验证。
查看日志这个process确实调度到了两个master。
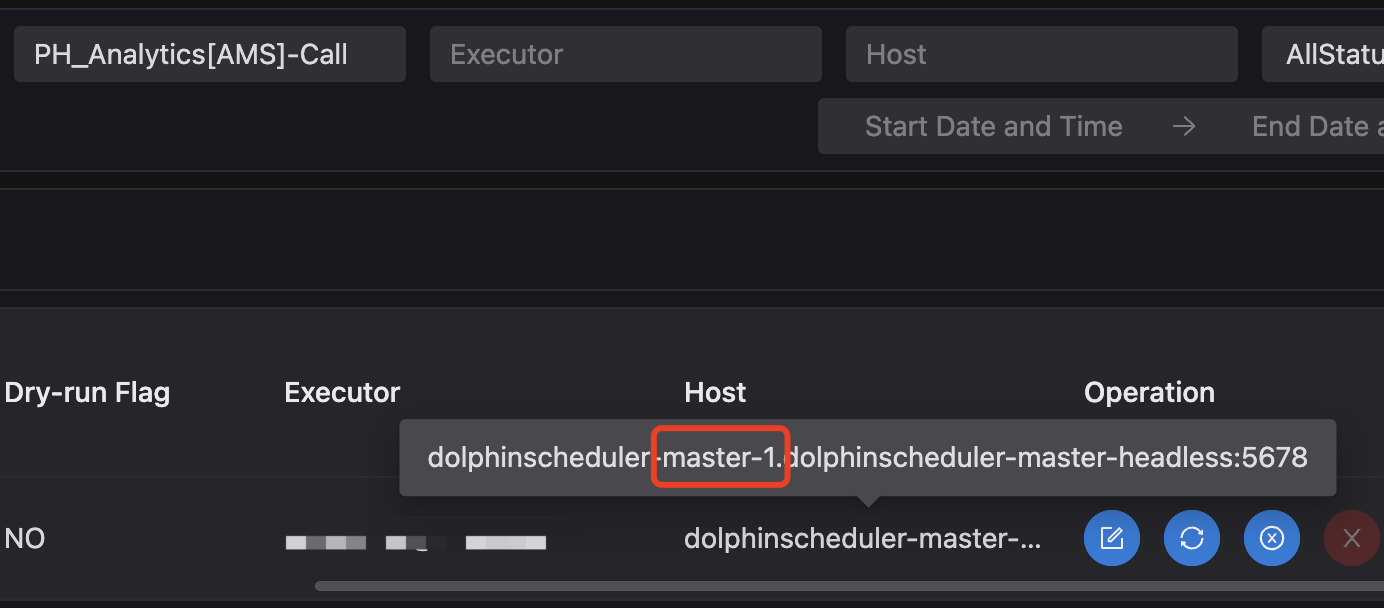
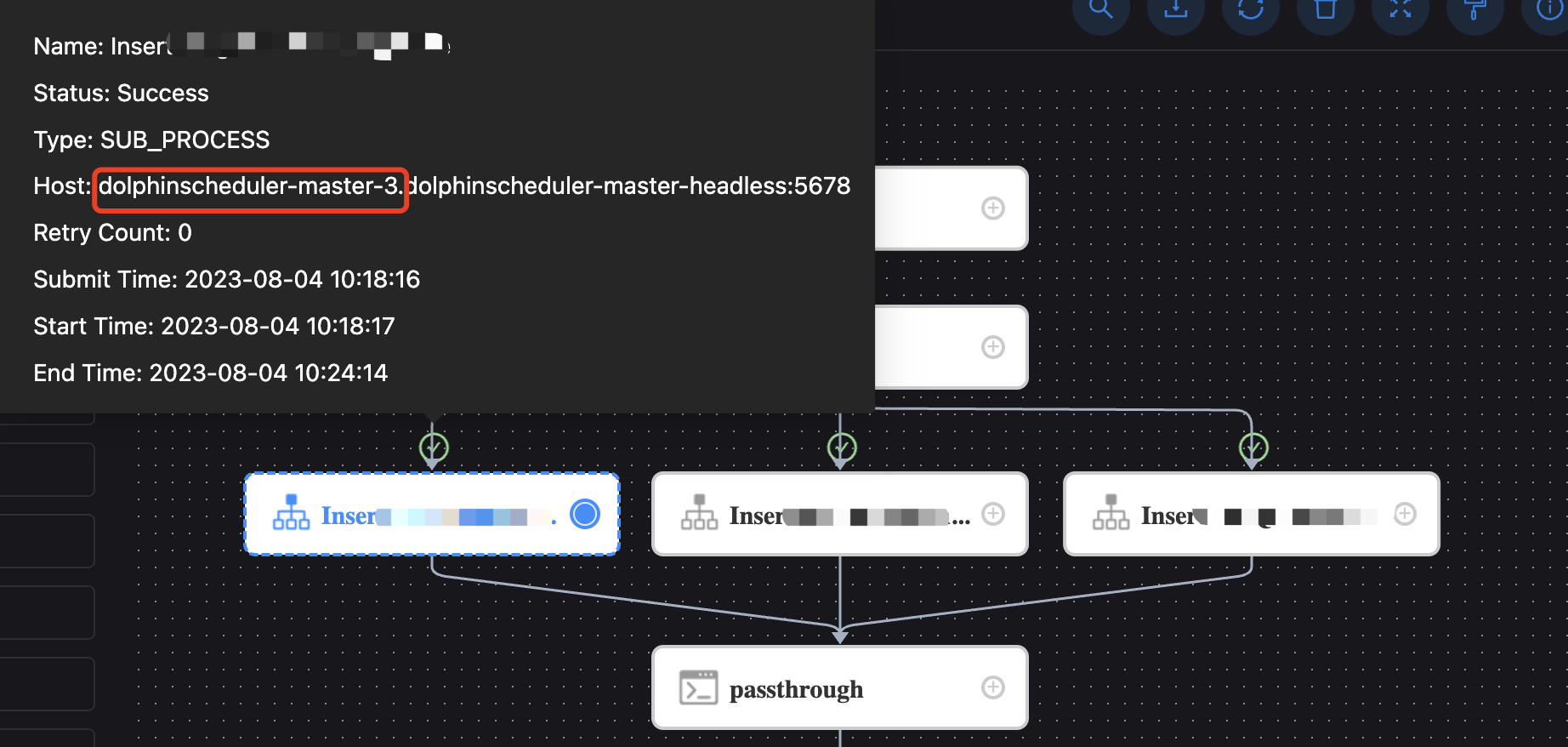
那子process在运行结束后在哪里回调的主master。
查看代码确实有这么个逻辑。
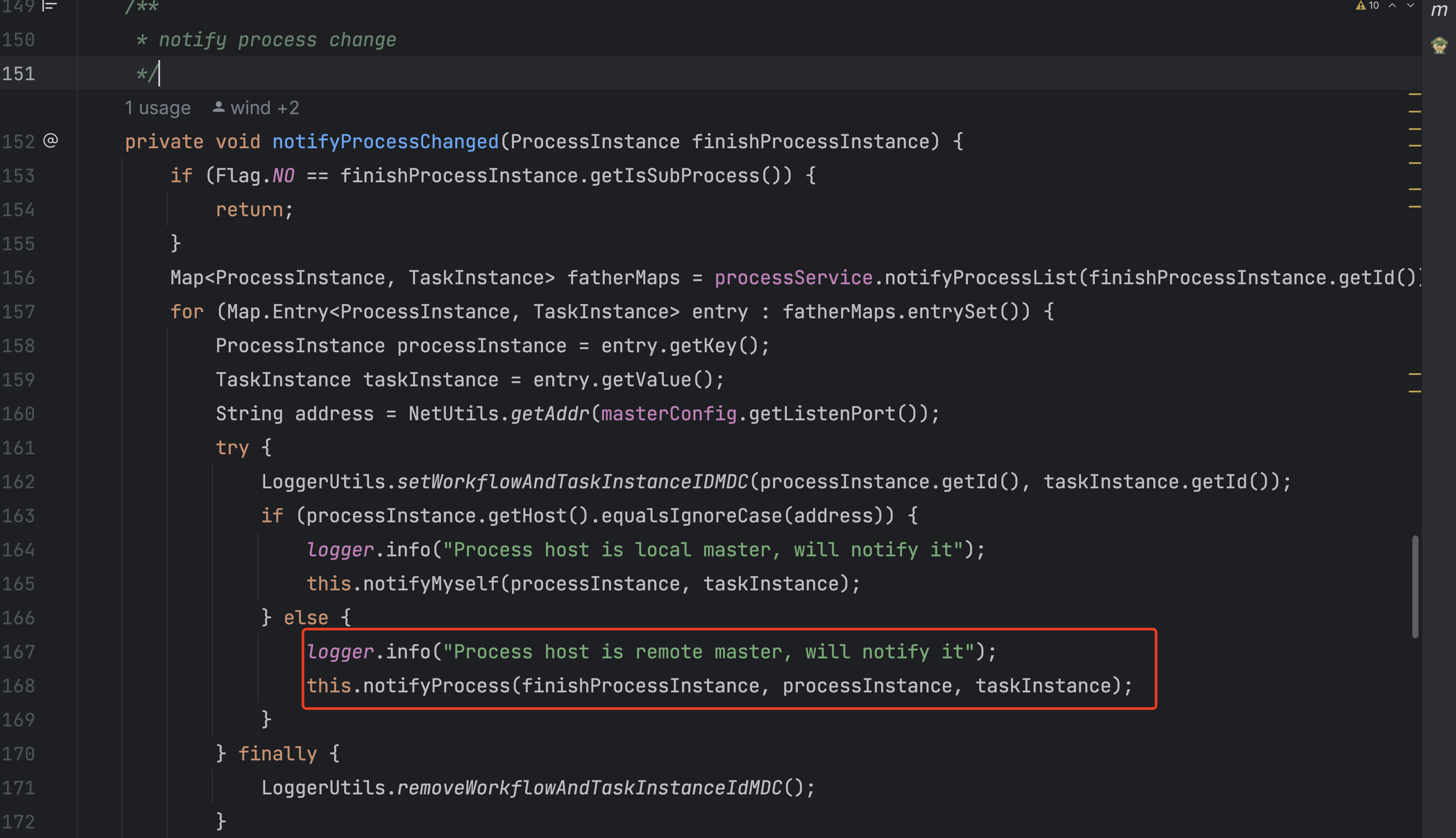
当时怀疑这款回调失败了,导致主master信息没更新。
但是查询日志后发现回调的逻辑是没问题的。

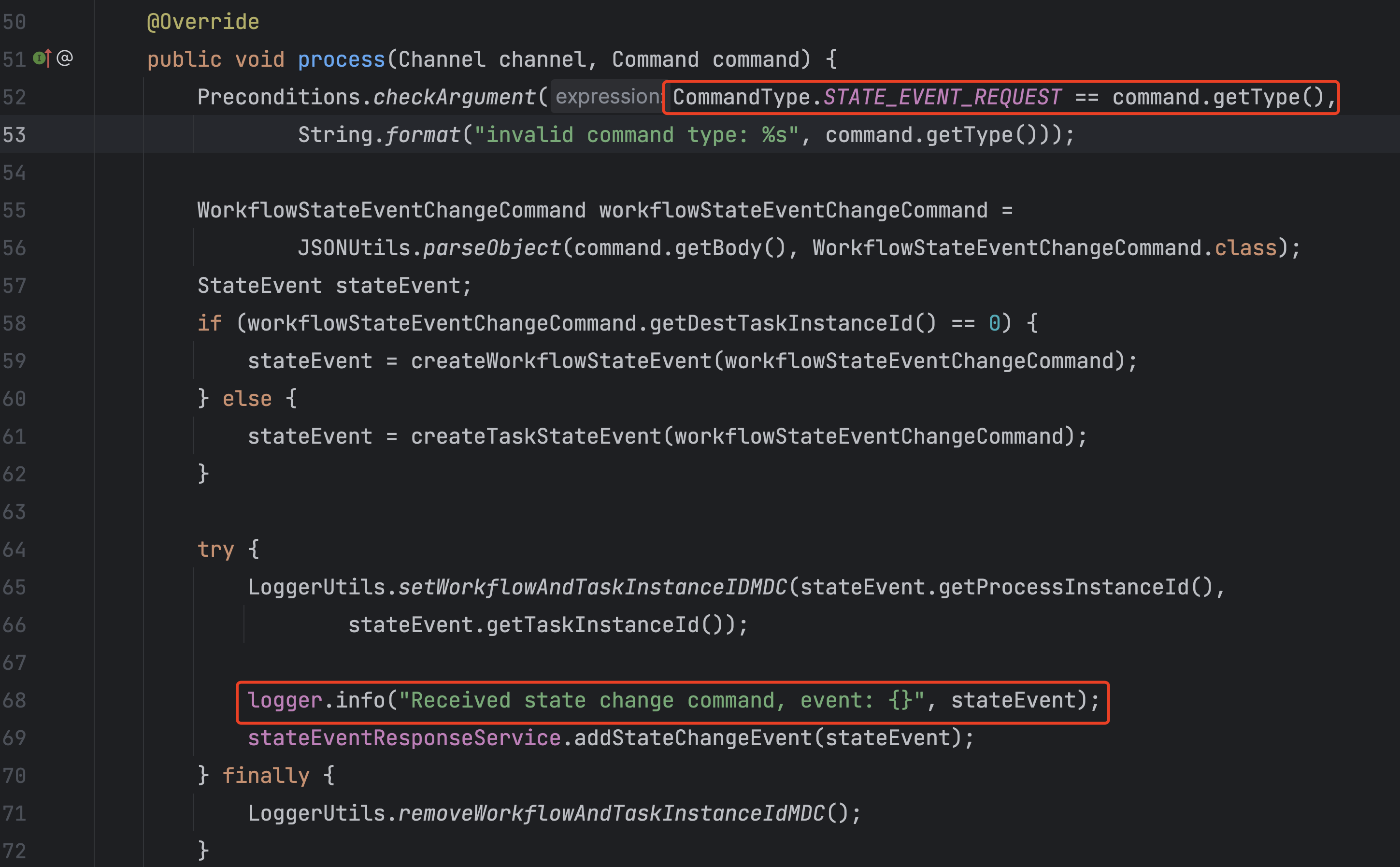
主master上也搜到了这行日志。
那问题就变成了,主master收到回调,但是更新状态出了问题。
于是查看代码寻找这块的逻辑。
通过查看代码,发现子process执行完,回调主master,回调的这个消息里面没有包含task所有的信息,所以我当时觉得去那就是主master更新task的地方出现了问题。
于是继续寻找,找到了一个逻辑。
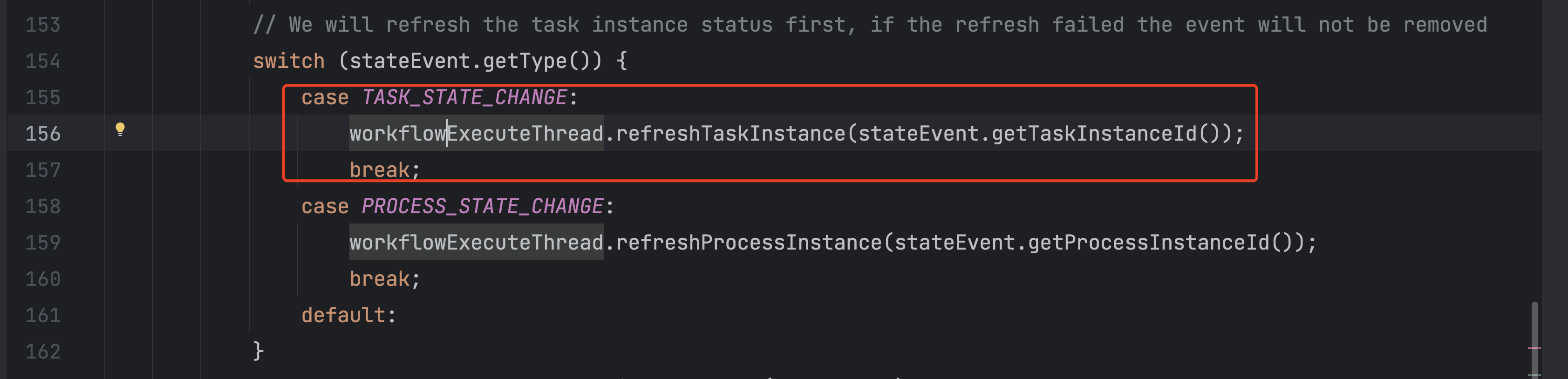
首先子process执行完,子master会把task的信息更新到db。
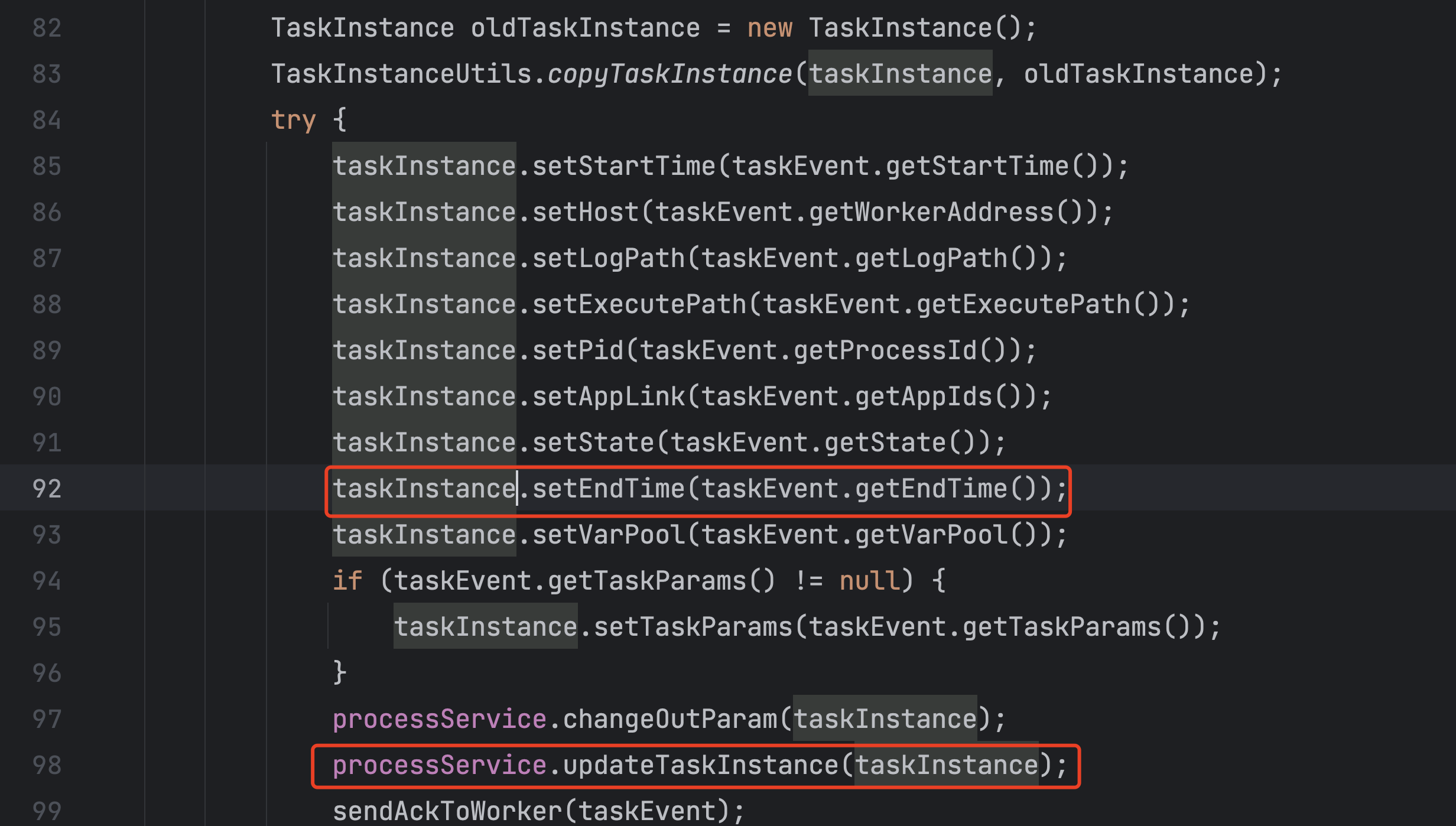
然后主master会通过db获取最新的task信息,放到内存中。
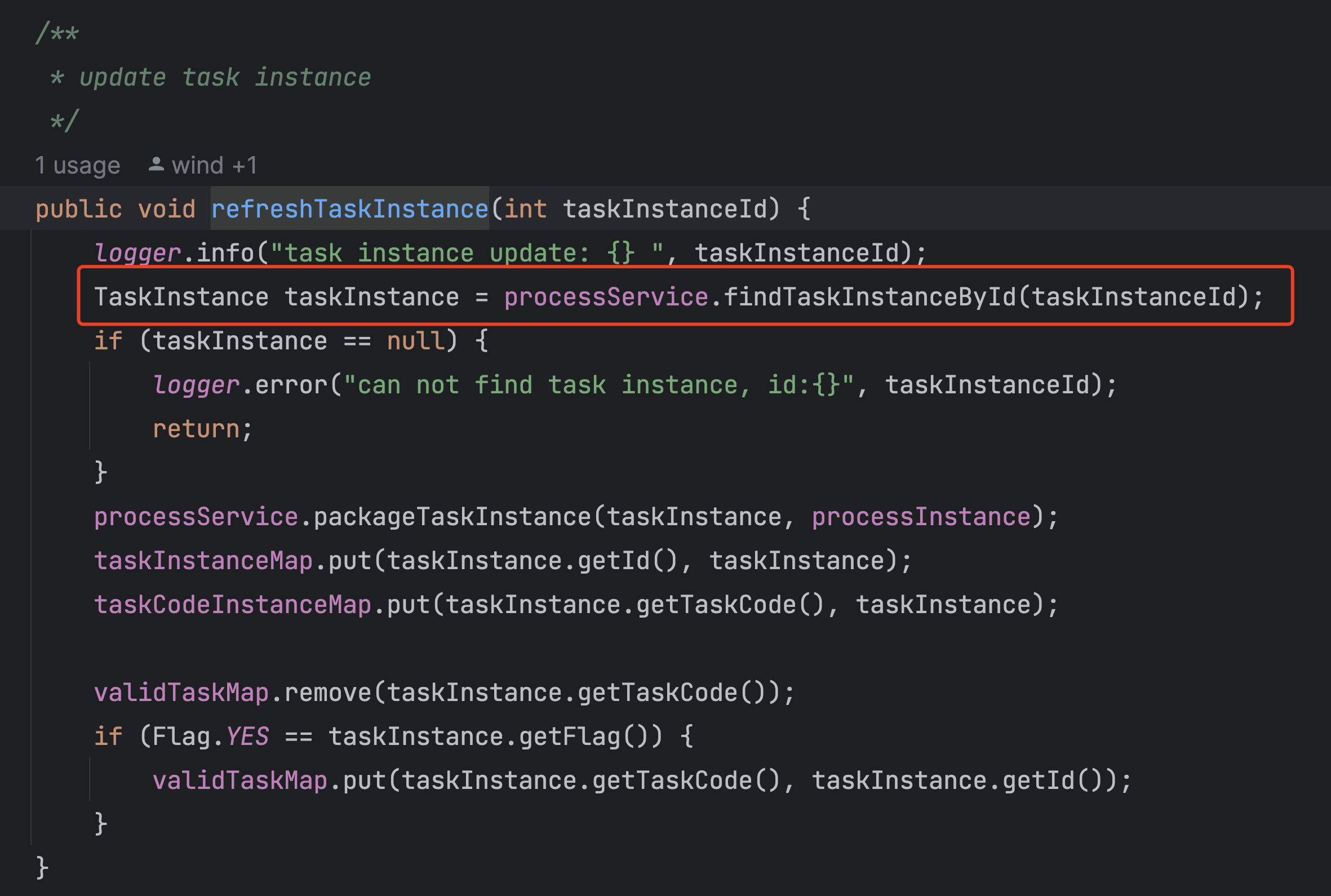
我当时怀疑这两个事件的顺序是不是有问题。
主master读取db中task信息更新到内存,然后子master才把信息同步到db。
但是有一点说不通,因为主master打印出来的task状态是更新过的,只有ent time没有更新。如果是两个事件顺序有问题,那么task的状态也不应该更新。
但是怀疑这个地方,就加个日志排查一下。
于是在主master从db更新的地方加了个日志,看一下两个事情的发生时间究竟是怎样的。
可以看到主master先从db读取数据,然后子master才把数据更新到db。
误差0.1s左右。
1 | 2023-09-05 02:11:51.719 +0000 [INFO] org.apache.dolphinscheduler.server.master.runner.WorkflowExecuteRunnable:[509] - [WorkflowInstance-720128][TaskInstance-960072] - task instance update: 960072 |

那是否是子master把数据部分更新到数据库?把task状态更新到db,然后主master读取到最新的状态,最后子master把end time更新到db。
虽然感觉这个概率不大,但是还是排查一下,不能放过任何一个可能。
流程很简单,我们在主master读取task的地方加一行日志,看一下读取出来的数据到底是什么。
1 | 2023-09-05 09:22:55.823 +0000 [INFO] org.apache.dolphinscheduler.server.master.runner.WorkflowExecuteRunnable:[509] - [WorkflowInstance-720128][TaskInstance-960072] - TaskInstance(id=960072, name=InsertAe, taskType=SUB_PROCESS, processInstanceId=720128, taskCode=10798843395461, taskDefinitionVersion=2, processInstanceName=null, processDefinitionName=null, taskGroupPriority=0, state=TaskExecutionStatus{code=1, desc='running'}, firstSubmitTime=Mon Sep 04 09:22:49 UTC 2023, submitTime=Mon Sep 04 09:22:49 UTC 2023, startTime=Mon Sep 04 09:22:52 UTC 2023, endTime=null, host=dolphinscheduler-master-0.dolphinscheduler-master-headless:5678, .......... |
可以看到TaskExecutionStatus未更新,endtime未更新。
跟我们预期的一样,子master写入是全部更新的task数据,不存在部分更新。
主master读取出来的就是更新之前的数据。
到这里,基本上我们怀疑的更新顺序的问题完全排除了。
说明一定有另一个地方,更新了主master内存里task的状态。
于是思路很清楚了,我们再重新看一下代码,主master收到更新的命令之后,做了什么事,哪里的代码更新了task的状态。
目标很明确,于是很快就找到了一个地方的代码。
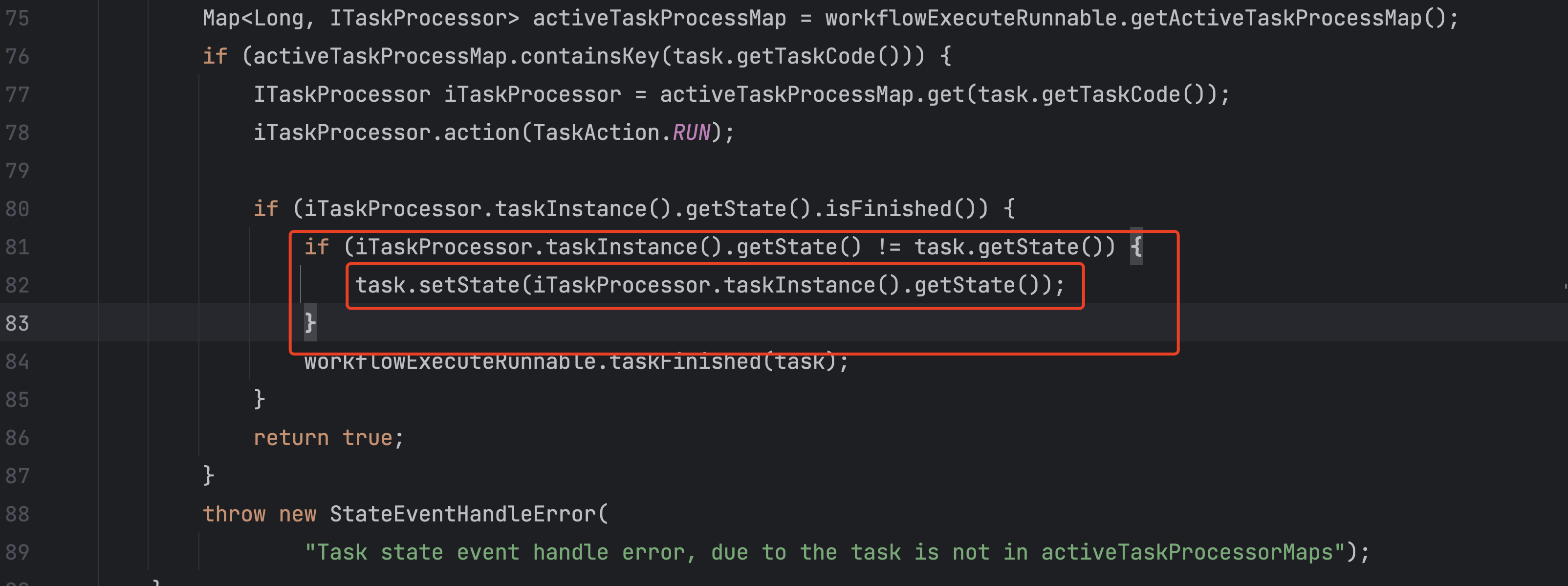
主master会通过子process的状态,更新内存对应的task的状态,但是这里没有更新end time。
对上了。
就是这里的问题,在有子process的时候会走这个逻辑,会不更新ent time然后报错。
为什么多个master才会触发,因为多个task会分配到不同的master上。
为什么执行1 2或者2 3不触发,这块应该跟调度规则有关系。具体的需要看一下具体是通过什么规则进行调度的。
问题找到了,其实很好修复,加一行代码就搞定。
重新打包部署测试,问题解决了。
至此,整个问题算是彻底解决了。
我们使用的ds3.1.1的版本,查看了一下社区最近的3.1.8的代码,还是有这个bug,于是提了一个pr修复了一下这个问题。
至于dev分支,这块的逻辑已经被全部重构了。
所以需要重新看一下代码,重新理解一下新的逻辑,看下是否还存在这个bug。
6、总结思考
回看整个过程,其实跌宕起伏。
因为很难复现,同时不同环境出现的截然不同的情况,也让人很迷惑,所以排查比较困难。
由于对整体核心调度逻辑的不了解,所以走了很多弯路,如果对整体消息传递的代码了解深刻一些,会更快的解决问题。
但是整体我们解决问题的思路和想法是没问题的,发现问题、定位问题、提出想法,然后求证、根据不同的结果来修正我们的思路,然后不断验证,直到解决。
回顾整个问题,其实触发的条件很苛刻。
首先需要一个大的process里面要有多个子process,然后还需要有参数透传的情况。需要集群模式部署,有多个master。
少一个,这个bug都不发生。
感谢用户,定义了这种复杂的工作流,发现bug,能让我们的平台更加稳定。